

[꼼꼼한 개발자] 꼼코더
42. 코드로 배우는 스프링 웹 프로젝트 - [페이징 처리] - order by 보다는 인덱스, PK_BOARD라는 인덱스, 인덱스를 이용하는 정렬 본문
42. 코드로 배우는 스프링 웹 프로젝트 - [페이징 처리] - order by 보다는 인덱스, PK_BOARD라는 인덱스, 인덱스를 이용하는 정렬
꼼코더 2023. 1. 28. 21:51🔑 order by 보다는 인덱스
이전에 ‘데이터가 많은 상태에 정렬 작업은 문제가 된다.’를 알아봤다.
이 문제를 해결하려면 일반적으로 ‘인덱스(index)를 이용한 정렬 생략 방법’이 있다.
결론부터 말하자면 ‘인덱스’라는 존재가 이미 정렬된 구조이므로
이를 이용해서 별도의 정렬을 하지 않는 방법을 일컫는다.
자세한 건 뒤에서 살펴보고, 우선 위와 같은 상황에서
다음과 같은 SQL을 실행해 보자.

결과를 보면 전체 테이블을 조사하고 정렬하는 것은 이전과 차이가 없이 동일하지만
실행시간의 차이는 매우 크게 확인할 수 있다.
가장 중요한 점은 SQL의 실행 시간이 거의 0초로 나온다는 점이다
실행 계획은 아래와 같다.

주의해서 봐야 하는 부분은
1) SORT를 하지 않았다
2) TBL_BOARD를 바로 접근지 않고 PK_BOARD를 이용해서 접근했다
3) RANGE SCAN DESCENDING, BY INDEX ROWID로 접근했다는 점이다.
🔑 PK_BOARD라는 인덱스
tbl_board 테이블 생성 SQL을 다시 살펴보도록 하자

테이블 생성시 제약 조건으로 PK를 지정하고 PK_board라고 지정했다.
데이터 베이스에서 PK는 상당히 중요한 의미인 ’ 식별자’의 의미와 ‘인덱스’의 의미를 가진다.
‘인덱스’는 말 그대로 ‘색인’이다.
우리가 가장 흔히 접하는 인덱슨는 도서 뒤쪽에 정리되어 있는 색인이다.
색인 이용시 사용자들은 색인만 보고 원하는 내용의 위치를 알 수 있다.
데이터베이스에서 인덱스를 가장 쉽게 이해하는 방법은
데이터베이스의 테이블을 하나의 책이라고 생각하고
어떻게 데이터를 찾거나 정렬하는지를 생각하는 것이다.
색인은 사람들이 쉽게 찾아볼 수 있게 ‘알파벳 순서’나 ‘한글 순서’로 정렬한다.
이를 통해 원하는 내용을 위에서부터 혹은 반대로 찾아나가는데 이를 ‘스캔(scan)’한다고 표현한다.
데이터 베이스에서 테이블을 만들 때 PK 부여 시 ‘인덱스’라는 것이 만들어진다.
PK 지정 이유는 ‘식별’에 의미가 있지만 구조상으로는 ‘인덱스’라는 존재(객체)가 만들어지는 것을 의미한다.
tb_board 테이블은 bno라는 칼럼을 기준으로 인덱스를 생성하게 된다.
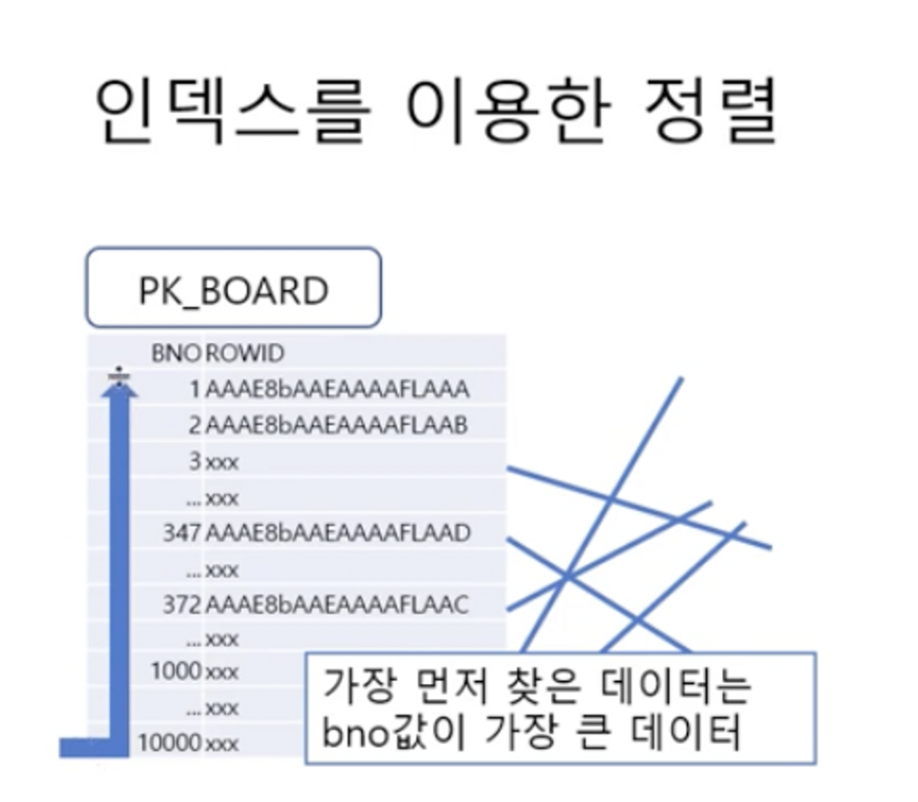
인덱스에는 순서가 있기 때문에 그림을 표현하면 아래와 같이 만들어진다.

그림의 왼쪽은 인덱스이고 오른쪽은 실제 테이블이다
왼쪽 그림을 보면 bno 값이 순서대로 정렬되어 있다.
오른쪽 그림은 마치 책장에 책을 막 넣은 것처럼 순서가 섞여있다.
인덱스와 실제 테이블을 연결하는 고리는 ROWID라는 존재이다.
ROWID는 데이터베이스 내의 주소에 해당하는데 모든 데이터는 자신만의 주소를 가지고 있다.
위에 그림을 정리하자면
우측의 테이블 데이터의 무작위로 된 BNO를 기준으로 모든 데이터를 스캔하면 너무 오래 걸린다.
하지만 이미 정렬된 BNO를 사용하여 ROWID 값과 일치한 데이터를 빠르게 정렬된 값으로 뽑을 수 있다.
👨🏻💻 간단 실습
SQL을 통해서 bno 값이 100번인 데이터를 찾고자 할 때에는
SQL은 ‘where bno = 100’과 같은 조건을 주게 된다.
이를 처리하려는 데이터베이스 입장에서는
tbl_board라는 책에서 bno 값이 100인 데이터를 찾아야 한다.
만약 책이 얇아 내용이 적다면 전체를 살펴보는 것이 더 빠를 수도 있다. 이를 데이터베이스 쪽에서는 ‘FULL SCAN’이라고 표현한다.
하지만 내용이 많고 색인이 존재한다면
색인을 찾고 색인에서 주소를 찾아서 접근하는 방식을 이용할 것이다.
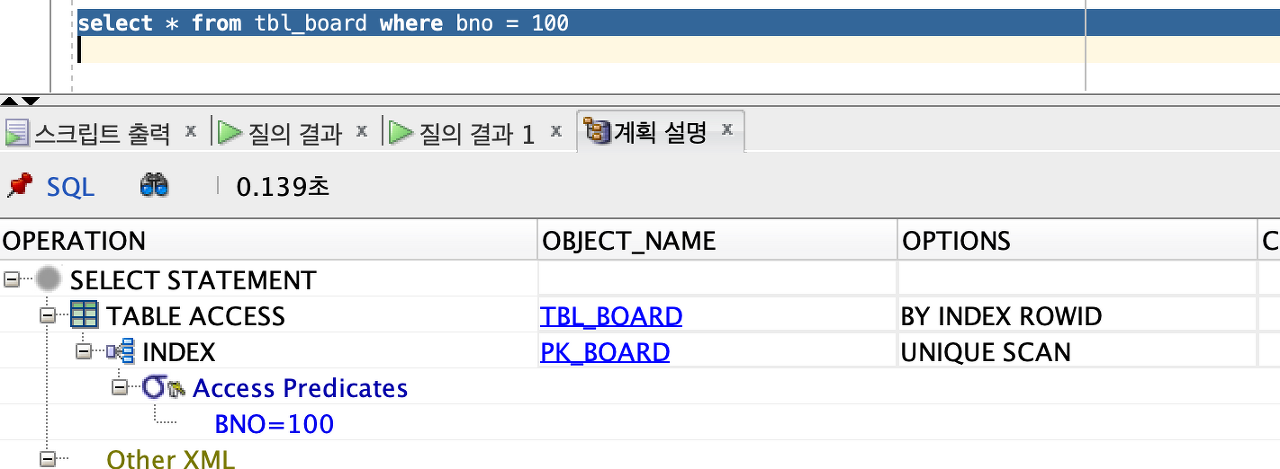
실행 계획을 통하여 데이터 베이스 속을 보자
안쪽을 보면 PK_BOARD는 인덱스이므로 먼저 인덱스를 이용해서
100번 데이터가 어디에 있는지 ROWID를 찾아내고
바깥쪽을 보면 ‘BY INDEX ROWID’라고 되어있는 말 그대로
ROWID를 통해서 테이블에 접근하게 된다.
🏘 인덱스를 이용하는 정렬
인덱스에서 가장 중요한 개념 중 하나는 ‘정렬이 되어 있다는 점’이다
정렬이 되어있어 데이터를 찾아 이들을 SORT 하는 과정을 생략할 수 있다.
‘bno의 역순으로 정렬한 결과’를 원한다면
이미 정렬된 인덱스를 이용해서 뒤에서부터 찾아 올라가는 방식을 이용하면 된다.
뒤에서 찾아 올라가는 개념은 DESCENDING을 말한다.
이전에 실행한 bno 역순으로 조회 시 실행 계획을 살펴보자
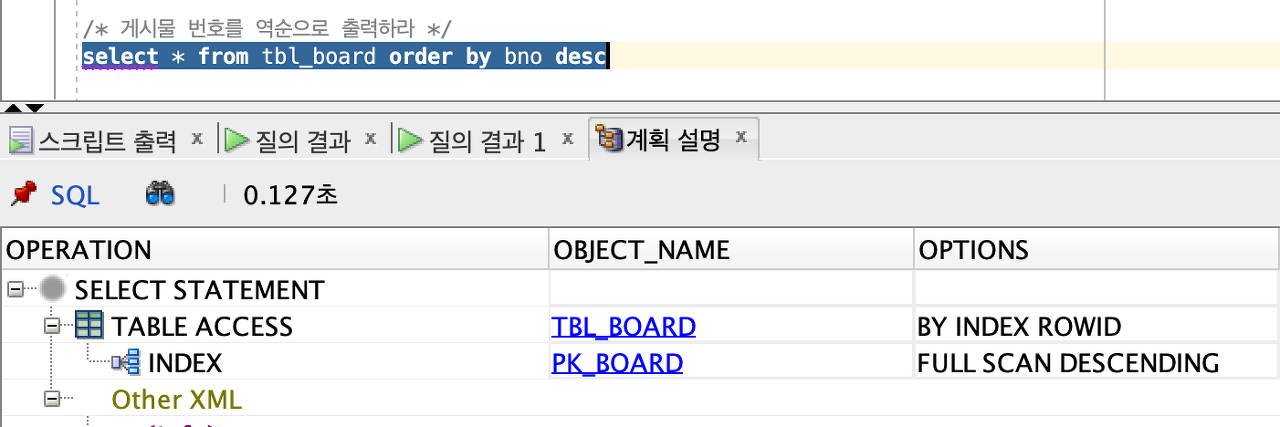
PK_BOARD라는 인덱스를 이용하는데 DESCENDING을 하고 있다.
만약 역순이 아닌 ‘bno의 순서대로 정렬’을 한다면 FULL SCAN이 된다.
해석 : “PK_BOARD에 INDEX를 뒤져서 ROWID를 이용해서 TBL_BOARD의 TABLE access 하는 방식”
그림으로 표현하면 아래와 같다
실무에서도 데이터의 양이 많고 정렬이 필요한 상황이라면
우선적으로 ‘인덱스’를 작성해야 한다
데이터의 양이 수천, 수만 개 정도의 정렬은 부하가 걸리지 않지만
그 이상의 데이터 처리 시 정렬을 하지 않는 방법에 대해서 고민해야 한다.
한 줄 요약 : order by를 쓰지 말라는 게 아니다 하지만 사용할 때를 구분하도록 하자.



